
Upsolver Simplifies Data Pipelines: Unleashing Efficiency and Scalability
The modern data landscape is characterized by an ever-increasing volume, velocity, and variety of information. Organizations are drowning in data, struggling to extract meaningful insights and drive business value. Traditional data pipelines, often built with complex, hand-coded ETL (Extract, Transform, Load) processes, are proving inadequate. They are time-consuming to build and maintain, prone to errors, and struggle to scale with growing data demands. Upsolver emerges as a transformative solution, fundamentally simplifying data pipelines and empowering businesses to leverage their data with unprecedented efficiency and scalability. By abstracting away much of the underlying complexity, Upsolver enables data teams to focus on delivering insights rather than wrestling with infrastructure.
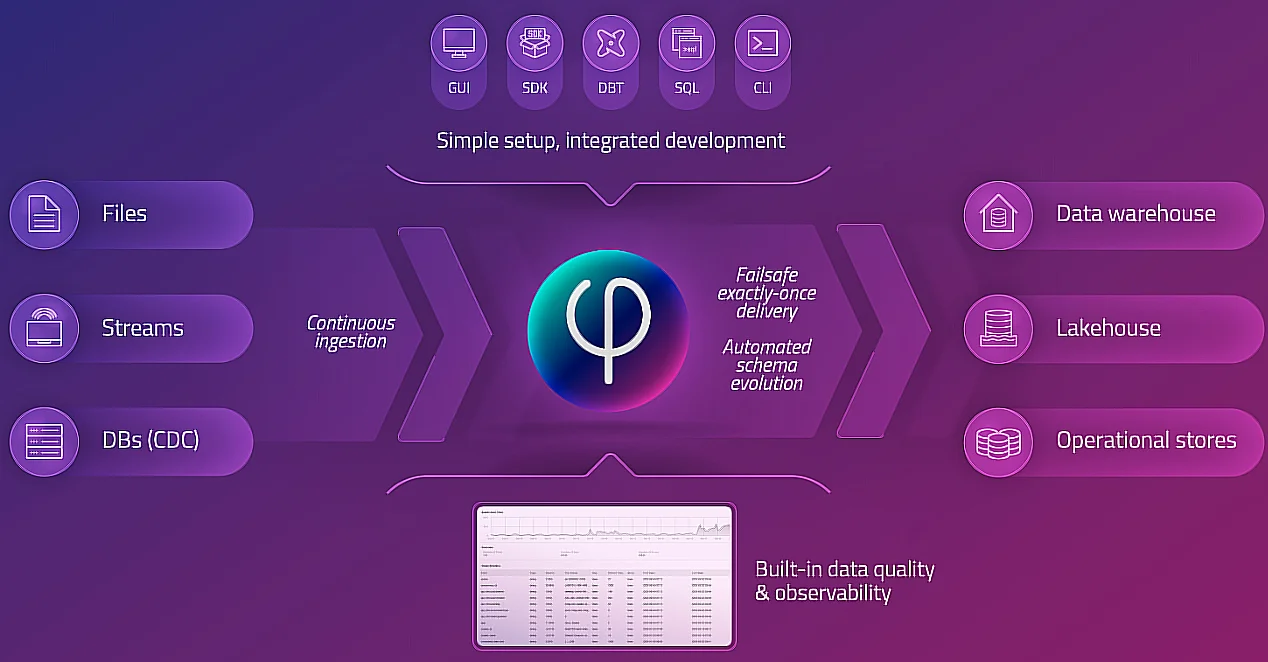
At its core, Upsolver is a cloud-native data pipeline platform designed for the age of big data. It streamlines the entire data lifecycle, from ingestion and transformation to cataloging and serving. Unlike conventional approaches that require deep expertise in distributed systems, coding languages like Python or Scala for Spark, and intricate infrastructure management, Upsolver leverages a declarative, SQL-centric approach. This means users can define their data transformations and pipeline logic using familiar SQL syntax, eliminating the need for extensive coding. This paradigm shift dramatically lowers the barrier to entry for data professionals, allowing analysts, data scientists, and even business users with SQL knowledge to build and manage sophisticated data pipelines. The platform is built on a foundation of open standards and cloud-native architectures, ensuring compatibility and avoiding vendor lock-in. Its design prioritizes performance, scalability, and cost-effectiveness, crucial considerations for any organization dealing with large-scale data operations.
One of the most significant pain points in traditional data pipelines is the complexity of data ingestion. Bringing data from a multitude of sources – databases, SaaS applications, streaming platforms, IoT devices, and flat files – into a central repository is often a cumbersome and error-prone process. Upsolver tackles this by providing a unified and streamlined ingestion framework. It supports a wide array of connectors, enabling seamless integration with diverse data sources without requiring custom scripts or complex configurations for each. The platform intelligently handles schema evolution, retries, and error handling, ensuring data is reliably captured and made available for processing. This eliminates a substantial manual effort and reduces the risk of data loss or corruption during the initial stages of the pipeline. Furthermore, Upsolver’s ability to ingest data in real-time, particularly from streaming sources, is a game-changer for organizations requiring up-to-the-minute insights for operational decision-making.
The transformation stage is where data is cleaned, enriched, and prepared for analysis. In traditional pipelines, this often involves writing complex code to perform joins, aggregations, filtering, and data type conversions. Upsolver democratizes this process through its SQL-based transformation engine. Users can define sophisticated data transformations using standard SQL queries, which are then translated and executed efficiently by the Upsolver platform. This declarative approach not only simplifies development but also enhances maintainability. Instead of deciphering intricate code, team members can understand and modify pipeline logic by reviewing SQL statements. Upsolver’s engine is optimized for performance on large datasets, leveraging distributed computing capabilities to process transformations at scale. It also offers features for data quality checks and validation, ensuring that transformed data is accurate and reliable before it is made available for downstream consumption. The platform’s ability to manage complex dependencies between transformations further simplifies the creation of multi-stage pipelines.
Data cataloging and governance are often afterthoughts in hastily built data pipelines, leading to data silos, confusion, and security risks. Upsolver integrates a robust data catalog as a first-class citizen within the platform. This catalog automatically discovers, documents, and organizes data assets as they are ingested and transformed. Users can easily search and understand available datasets, their schemas, lineage, and ownership. This enhanced discoverability fosters collaboration and self-service analytics, empowering users to find the data they need without relying on IT or data engineering teams for every request. More importantly, the integrated catalog provides a centralized point for data governance and security. Access controls, data masking, and auditing capabilities can be applied at the dataset level, ensuring compliance with regulatory requirements and protecting sensitive information. The lineage tracking capabilities within Upsolver are particularly valuable, providing a clear audit trail of data transformations from source to consumption, which is critical for debugging, compliance, and understanding data impact.
Scalability is a fundamental requirement for any modern data pipeline. As data volumes grow exponentially, pipelines must be able to handle increased load without performance degradation or significant cost overruns. Upsolver is built with cloud-native scalability in mind. It leverages the elastic compute and storage capabilities of major cloud providers to automatically scale resources up or down based on demand. This means organizations can start with a small footprint and effortlessly scale their data pipelines as their data needs grow, without needing to re-architect their systems. This elasticity is particularly beneficial for handling unpredictable data spikes and seasonal workloads, ensuring consistent performance and cost optimization. The platform’s architecture is designed for parallel processing, enabling it to handle massive datasets and complex transformations with speed and efficiency.
The operational overhead associated with managing data pipelines can be a significant burden on IT and data engineering teams. Upsolver dramatically reduces this burden by automating many of the tasks involved in pipeline management. This includes automated deployment, monitoring, alerting, and self-healing capabilities. The platform provides comprehensive dashboards and logging, giving users full visibility into pipeline performance, status, and potential issues. When problems arise, Upsolver’s automated alerting and remediation features can often resolve them proactively, minimizing downtime and the need for manual intervention. This operational simplification frees up valuable resources, allowing data teams to focus on higher-value activities such as data analysis, model development, and business strategy. The reduction in manual operational tasks also leads to a significant decrease in the likelihood of human error, further improving pipeline reliability.
Cost optimization is a critical concern for any data-driven organization. Building and maintaining complex, on-premises or custom cloud data pipelines can incur substantial infrastructure, development, and operational costs. Upsolver’s cloud-native architecture and intelligent resource management contribute to significant cost savings. By utilizing elastic cloud resources and optimizing query execution, Upsolver ensures that users only pay for the compute and storage they actively consume. The elimination of extensive custom coding and the reduction in operational overhead also translate into lower labor costs. Furthermore, the platform’s efficiency in processing and transforming data means that insights can be generated faster and more cost-effectively, leading to a quicker return on data investment. The ability to provision and de-provision resources on demand prevents over-provisioning and associated wasted expenditure.
The future of data pipelines is one of simplicity, accessibility, and intelligence. Upsolver is at the forefront of this evolution. By abstracting away the complexities of infrastructure management, coding, and operational overhead, Upsolver empowers organizations to unlock the full potential of their data. Its SQL-centric approach democratizes data pipeline development, making it accessible to a wider range of users. The platform’s integrated data catalog, robust governance features, and inherent scalability ensure that data is not only accessible but also secure, discoverable, and ready for advanced analytics. For businesses looking to accelerate their data initiatives, reduce operational costs, and gain a competitive edge through data, Upsolver offers a compelling and transformative solution that simplifies the complex world of data pipelines and unleashes the power of information. The continuous innovation within the Upsolver platform further enhances its value proposition, with ongoing development focusing on AI-driven pipeline optimization, advanced analytics integrations, and expanded connector capabilities. This commitment to evolution ensures that Upsolver remains a leading solution for modern data challenges.

{kind=link}