
AI Inference Acceleration on CPUs
The increasing demand for AI capabilities across diverse applications, from real-time analytics and edge computing to embedded systems and large-scale data centers, has placed a significant emphasis on efficient AI inference. While specialized hardware like GPUs and TPUs have traditionally dominated high-performance AI workloads, leveraging the ubiquitous nature and cost-effectiveness of CPUs for inference acceleration is a critical and rapidly evolving area. This article delves into the strategies, techniques, and hardware advancements that enable high-performance AI inference directly on Central Processing Units (CPUs), exploring both software-centric optimizations and hardware-specific features that unlock significant performance gains.
At its core, AI inference involves executing a pre-trained neural network model to make predictions on new, unseen data. This process is computationally intensive, primarily involving a series of matrix multiplications and element-wise operations. The efficiency of these operations on a CPU is directly tied to its architecture, instruction set capabilities, and memory hierarchy. Traditional CPU architectures, designed for general-purpose computing, often lack the massive parallelism inherent in specialized AI accelerators. However, modern CPUs have evolved significantly, incorporating features specifically beneficial for AI inference, such as wider vector units, dedicated AI instructions, and improved memory bandwidth.
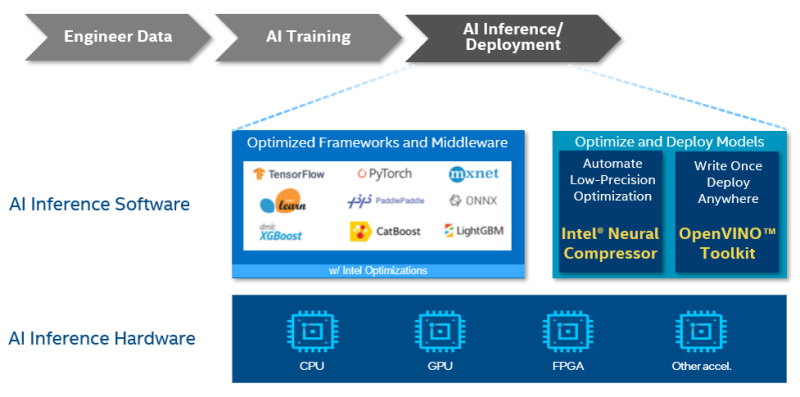
One of the most impactful software-centric approaches to AI inference acceleration on CPUs is the use of optimized inference engines and libraries. Frameworks like TensorFlow Lite, PyTorch Mobile, ONNX Runtime, and Intel’s OpenVINO are specifically designed to run AI models efficiently on a wide range of hardware, including CPUs. These engines employ numerous techniques, including operator fusion, kernel optimization, and memory layout transformations, to reduce computational overhead and improve data locality. Operator fusion, for instance, combines multiple individual operations (e.g., convolution followed by ReLU activation) into a single, more efficient kernel, thereby reducing the number of kernel launches and memory accesses. Kernel optimization involves hand-tuning the implementation of fundamental operations (like matrix multiplication) to exploit specific CPU instruction sets and cache behaviors.
Quantization is another cornerstone of CPU-based AI inference acceleration. It involves reducing the precision of model weights and activations from floating-point representations (e.g., FP32) to lower-precision formats like INT8 or even binary values. This reduction in precision offers several advantages: it significantly decreases the memory footprint of the model, leading to lower memory bandwidth requirements and faster data loading; it reduces the computational cost of arithmetic operations, as integer operations are generally faster and consume less power than floating-point operations on CPUs; and it enables the use of specialized, low-precision integer instructions that are often available on modern CPUs. Tools within inference frameworks and dedicated quantization libraries facilitate this process, offering techniques like post-training quantization (PTQ) and quantization-aware training (QAT) to minimize accuracy degradation.
Vectorization, the ability of a CPU to perform the same operation on multiple data elements simultaneously, is paramount for AI inference acceleration. Modern CPUs feature powerful Single Instruction, Multiple Data (SIMD) instruction sets like SSE, AVX, AVX2, and AVX-512. These instruction sets allow a single instruction to operate on vectors of data, such as 8, 16, or 32 32-bit floating-point numbers or 16, 32, or 64 8-bit integers. Inference engines and optimized libraries heavily leverage these SIMD instructions to execute the element-wise operations and matrix multiplications that form the backbone of neural networks. For example, a matrix multiplication can be broken down into a series of vector dot products, where each vector operation is executed in parallel across multiple data elements.
Beyond SIMD, newer CPU architectures are introducing dedicated AI acceleration instructions. Intel’s Advanced Matrix Extensions (AMX) found in their 3rd and 4th generation Xeon Scalable processors, for instance, provide specialized hardware units for matrix operations, significantly boosting performance for deep learning workloads. AMX introduces new registers and instructions designed to load, compute, and store sub-tiled matrices efficiently, enabling higher throughput for common deep learning operations like convolutions and fully connected layers. Similarly, ARM’s Scalable Vector Extension (SVE) and SVE2 offer programmable vector length and enhanced data processing capabilities, beneficial for a wide range of scientific and AI workloads.
Thread-level parallelism is another critical aspect of CPU inference. Modern CPUs possess multiple cores, and inference tasks can be effectively parallelized across these cores. Inference engines employ sophisticated threading strategies to distribute the computational load. This can involve parallelizing computations across different layers of the network, splitting individual layer computations across multiple threads, or even distributing batches of inference requests across available cores. Efficient synchronization mechanisms and load balancing are crucial to avoid contention and ensure optimal utilization of all available CPU cores.
Memory hierarchy optimization plays a vital role in inference performance. CPUs rely on a multi-level cache system (L1, L2, L3) to reduce the latency of accessing data from main memory. Effective inference implementations strive to keep frequently accessed model parameters and intermediate activations within the CPU caches. Techniques such as loop tiling, data prefetching, and careful memory layout (e.g., using contiguous memory blocks for matrices) help improve cache hit rates. For models with large memory footprints, optimizing data movement between main memory and caches becomes a significant bottleneck, and techniques that minimize this movement are essential.
The choice of data types for model representation and computation has a profound impact on CPU inference performance. As previously mentioned, INT8 quantization is highly effective. However, the specific integer data types used (e.g., signed vs. unsigned, different bit widths) can influence the efficiency of instruction execution and the ability to leverage specialized instructions. Moreover, for certain operations where accuracy is paramount, mixed-precision inference, where some layers use higher precision (e.g., FP16 or BF16) and others use lower precision (e.g., INT8), can offer a good balance between performance and accuracy. BF16 (Bfloat16) is particularly interesting as it offers the same dynamic range as FP32 while using 16 bits, making it suitable for deep learning training and inference without extensive retraining.
Graph optimization is a crucial step in preparing an AI model for efficient inference. This process, often performed by inference engines or model compilers, involves analyzing the computational graph of the neural network and applying transformations to enhance performance. This includes removing redundant operations, reordering operations for better data locality or parallel execution, and optimizing the flow of data through the graph. Techniques like constant folding (pre-computing constant values) and dead code elimination contribute to a more streamlined and computationally efficient graph.
Hardware-specific optimizations are increasingly being integrated into CPU architectures to directly support AI workloads. These can range from enhanced branch prediction and out-of-order execution units that are better suited for the irregular control flow of some AI algorithms, to specialized memory controllers that can handle high memory bandwidth demands. Furthermore, the integration of dedicated AI accelerators or NPU (Neural Processing Unit) blocks within CPUs, as seen in some mobile and edge processors, represents a convergence of general-purpose and specialized computing, allowing for heterogeneous inference.
Model pruning and knowledge distillation are complementary techniques that can also contribute to CPU-friendly inference. Model pruning involves removing redundant weights or neurons from a pre-trained model, thereby reducing its size and computational requirements without a significant loss in accuracy. Knowledge distillation, on the other hand, involves training a smaller, more efficient "student" model to mimic the behavior of a larger, more complex "teacher" model. This allows for the deployment of smaller, faster models on resource-constrained CPUs.
The evolving landscape of CPU architectures, coupled with advancements in software optimization techniques, continues to push the boundaries of AI inference performance on these ubiquitous processors. For developers and researchers seeking to deploy AI models efficiently without relying on specialized hardware, understanding and applying these strategies—from leveraging optimized inference engines and quantization to exploiting vectorization, dedicated AI instructions, and efficient memory management—is paramount. As AI permeates more aspects of our digital lives, the role of the CPU as a capable and cost-effective inference engine will only continue to grow in importance. The continuous development of both hardware and software is essential for unlocking the full potential of CPUs for AI inference across a wide spectrum of applications, from the smallest edge devices to the most powerful data centers.

{kind=link}