
Tagging Natural Language Processing: A Deep Dive into Annotation, Techniques, and Applications
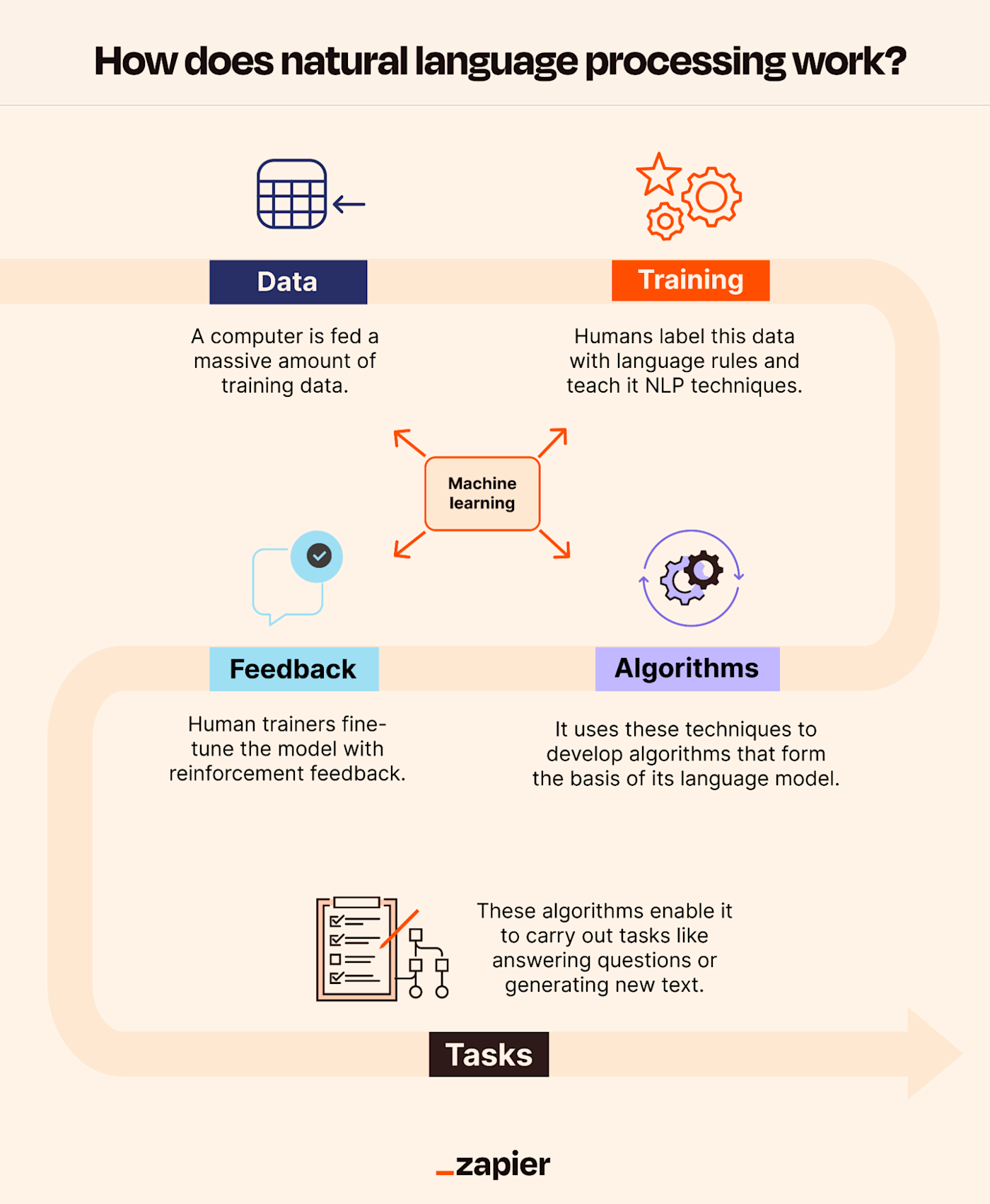
Tagging in Natural Language Processing (NLP) refers to the process of assigning labels or "tags" to linguistic units, such as words, phrases, sentences, or even entire documents, to represent their grammatical, semantic, or contextual properties. This fundamental task underpins a vast array of NLP applications, enabling machines to understand, interpret, and process human language with increasing sophistication. The effectiveness of any NLP system is heavily reliant on the quality and accuracy of the tagging process, making it a cornerstone of research and development in the field. Tagging transforms unstructured text into structured data, unlocking its potential for analysis, retrieval, and generation.
At its core, tagging in NLP involves creating a system of predefined categories (tags) and a set of rules or models that can automatically assign these tags to textual elements. The complexity of tagging ranges from simple part-of-speech (POS) tagging, which identifies the grammatical role of each word (e.g., noun, verb, adjective), to more intricate forms of semantic role labeling (SRL), which aims to identify the predicate-argument structure of a sentence, and named entity recognition (NER), which identifies and classifies named entities like people, organizations, and locations. The choice of tags and the method of assignment are dictated by the specific NLP task at hand. For instance, a sentiment analysis system might tag words or phrases as "positive," "negative," or "neutral," while a machine translation system might require POS tags to ensure grammatical correctness in the translated output.
One of the most foundational and widely implemented tagging techniques is Part-of-Speech (POS) tagging. POS tagging assigns a specific grammatical category to each word in a sentence. Common POS tags include noun (NN), verb (VB), adjective (JJ), adverb (RB), pronoun (PRP), preposition (IN), conjunction (CC), and interjection (UH). More detailed tagsets exist, such as the Penn Treebank tagset, which further distinguishes between singular and plural nouns, different verb tenses, and comparative/superlative adjectives. POS tagging is typically performed using statistical models, often based on Hidden Markov Models (HMMs) or Conditional Random Fields (CRFs). These models learn from large annotated corpora (datasets) to predict the most likely POS tag for a word given its context. For example, the word "run" can be a verb or a noun. A POS tagger will analyze the surrounding words to determine its grammatical function. If the sentence is "I will run a marathon," "run" is a verb. If it’s "The run was exhilarating," "run" is a noun. The accuracy of POS taggers has significantly improved over the years, with state-of-the-art systems achieving accuracy rates exceeding 97%. This accuracy is crucial for subsequent NLP tasks that rely on grammatical understanding.
Beyond grammatical roles, Named Entity Recognition (NER) is another critical tagging task. NER focuses on identifying and classifying specific categories of entities within text. These categories typically include: Person (PER), Organization (ORG), Location (LOC), Date (DATE), Time (TIME), Money (MONEY), Percentage (PERCENT), and miscellaneous entities. NER is vital for information extraction, knowledge graph construction, and building search engines that can understand the entities being queried. For instance, in the sentence "Apple announced its new iPhone in California," an NER system would identify "Apple" as an Organization, "iPhone" as a Product (or a specific entity type), and "California" as a Location. NER models are often built using supervised learning techniques, employing sequence labeling models like CRFs, recurrent neural networks (RNNs), and more recently, transformer-based models like BERT and RoBERTa. These models learn to recognize patterns and contextual clues that indicate the presence and type of named entities. The effectiveness of NER heavily depends on the granularity of the entity types defined and the richness of the training data.
Semantic Role Labeling (SRL) goes a step further than POS tagging by identifying the underlying semantic relationships between words in a sentence, particularly the predicate-argument structure. A predicate is typically a verb, and its arguments are the participants in the action or state described by the verb. SRL aims to answer questions like "who did what to whom, where, when, and why?" For example, in the sentence "John ate the apple with a fork," SRL would identify "ate" as the predicate, "John" as the agent (who ate), "the apple" as the patient (what was eaten), and "with a fork" as an instrumental modifier. SRL systems are often built using deep learning models, leveraging the power of semantic parsing and often incorporating information from POS tags and dependency parses. SRL is crucial for tasks requiring deeper understanding of sentence meaning, such as question answering, summarization, and machine translation where conveying the correct semantic relationships is paramount.
The process of creating tagged data, known as annotation, is a labor-intensive but indispensable aspect of supervised NLP. Humans meticulously read and assign tags to text based on predefined guidelines. The quality of these guidelines and the consistency of the annotators directly impact the performance of the resulting NLP models. Annotation platforms and tools have been developed to streamline this process, offering features like inter-annotator agreement metrics to ensure consistency. Active learning techniques are also employed to optimize the annotation process by intelligently selecting the most informative instances for human annotation, thereby reducing the overall annotation effort. Challenges in annotation include ambiguity in language, the subjective nature of some tagging tasks (e.g., sentiment analysis), and the need for domain expertise for specialized tagging.
Beyond manual annotation, unsupervised and semi-supervised learning approaches are gaining traction in tagging. Unsupervised methods aim to discover patterns and categories in data without explicit human labeling, often through clustering or topic modeling. Semi-supervised methods combine a small amount of labeled data with a large amount of unlabeled data, leveraging the unlabeled data to improve model generalization. Techniques like co-training and self-training fall under this category. For example, a model might be trained on a small set of POS-tagged sentences and then used to tag a larger corpus, with the high-confidence predictions being added to the training set for further refinement.
The evolution of tagging in NLP has been closely intertwined with advancements in machine learning, particularly deep learning. Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRUs) have been instrumental in capturing sequential dependencies in text, leading to significant improvements in tagging accuracy. More recently, transformer-based architectures, such as BERT, GPT, and their variants, have revolutionized NLP, including tagging. These models, pre-trained on massive datasets, possess a deep understanding of language context and can be fine-tuned for specific tagging tasks with remarkably high performance. Their ability to process input in parallel and capture long-range dependencies has made them the de facto standard for many state-of-the-art tagging systems.
Several types of tags are employed in NLP, each serving a distinct purpose:
- Part-of-Speech (POS) Tags: Identify the grammatical category of words (noun, verb, adjective, etc.).
- Named Entity Recognition (NER) Tags: Classify named entities (person, organization, location, date, etc.).
- Chunking/Shallow Parsing Tags: Identify and group words into syntactically meaningful phrases (noun phrases, verb phrases). This is often represented using IOB (Inside, Outside, Beginning) or BIOES (Beginning, Inside, Outside, End, Single) tagging schemes.
- Semantic Role Labeling (SRL) Tags: Identify the predicate-argument structure of sentences, labeling participants of a verb.
- Dependency Parsing Tags: Indicate the grammatical relationships between words, often represented as head-dependent links.
- Sentiment Analysis Tags: Classify the emotional tone of text (positive, negative, neutral) or finer-grained emotions.
- Topic Tags: Assign broad thematic categories to documents or sentences.
- Discourse Markers: Tag words or phrases that indicate relationships between sentences or clauses, such as "however," "therefore," or "in addition."
- Coreference Resolution Tags: Link mentions of the same entity across a text. For example, identifying that "he" refers to "John" in a previous sentence.
The applications of tagging in NLP are extensive and continue to grow:
- Information Extraction: NER and SRL are fundamental to extracting structured information from unstructured text, enabling the creation of databases and knowledge graphs.
- Search Engines: Tagging improves search relevance by understanding the entities, concepts, and relationships within queries and documents.
- Machine Translation: POS tagging and dependency parsing are essential for generating grammatically correct and semantically accurate translations.
- Sentiment Analysis: Tagging emotions and opinions allows businesses to monitor brand perception, customer feedback, and market trends.
- Question Answering Systems: Understanding the entities and relationships within questions and answer passages, facilitated by NER and SRL, is crucial for accurate responses.
- Text Summarization: Identifying key entities and semantic roles helps in extracting the most important information for generating concise summaries.
- Chatbots and Virtual Assistants: Tagging enables these systems to understand user intent, extract relevant information from queries, and generate appropriate responses.
- Content Moderation: Tagging can identify offensive, inappropriate, or spam content in online platforms.
- Grammar Checking and Spell Correction: POS tagging is a cornerstone of these tools, helping to identify grammatical errors and suggest corrections.
- Text Classification: While not strictly a tagging task at the word level, the output of tagging (e.g., presence of certain entities or sentiment scores) can be used as features for text classification.
Challenges in tagging NLP remain, despite significant progress. Ambiguity is a pervasive issue; words can have multiple meanings and grammatical functions, requiring sophisticated disambiguation techniques. Domain-specific language, slang, and evolving linguistic trends pose ongoing challenges for models trained on general corpora. The need for large, high-quality annotated datasets for supervised learning is a significant bottleneck, driving research into more efficient annotation methods and unsupervised/semi-supervised techniques. Furthermore, the interpretability of deep learning models used for tagging can be a concern, making it difficult to understand why a particular tag was assigned. Future research in tagging NLP will likely focus on developing more robust models that can handle linguistic variation, reducing reliance on massive annotated datasets, improving interpretability, and extending tagging capabilities to less-resourced languages. The ongoing pursuit of more nuanced and accurate language understanding hinges on the continued advancement of tagging techniques within Natural Language Processing.

{kind=link}